Plataforma expert.ai: inteligencia integrada desde el principio con contextos específicos de cada dominio
Manejar bien el lenguaje es difícil. Dar sentido a la jerga propia de cada sector, público o privado, o a la terminología de los productos de una empresa o institución y extraer información útil con la rapidez y flexibilidad necesarias aún lo es más. O lo era.
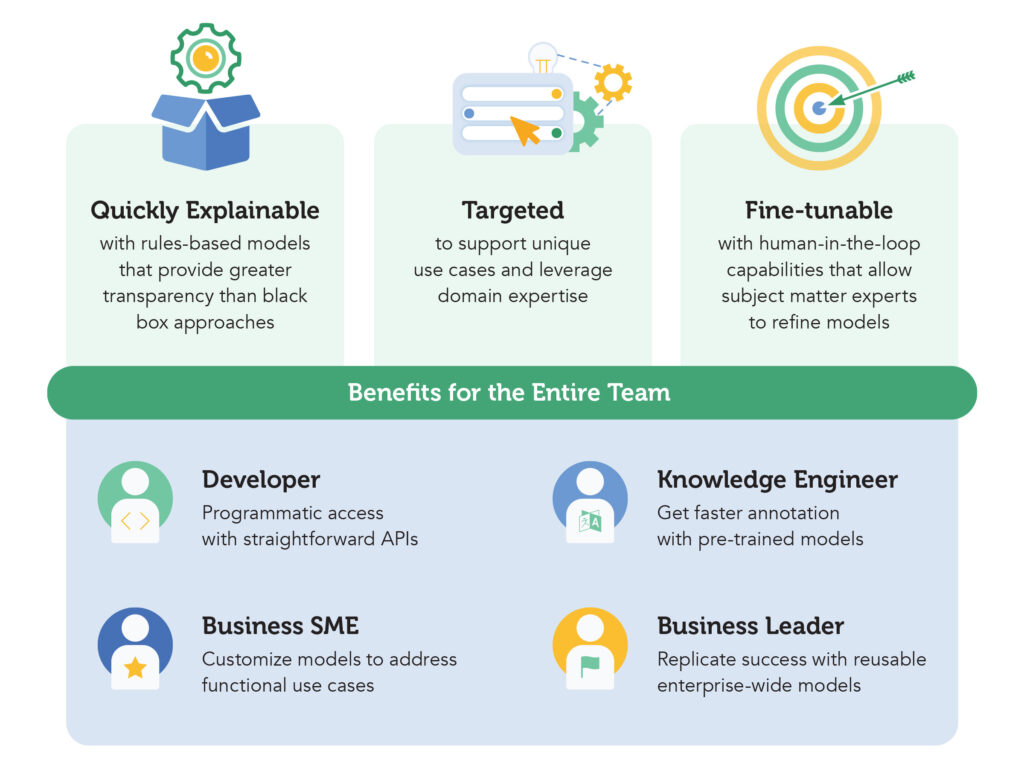
Con más de 300 soluciones de procesamiento del lenguaje implantadas con éxito, expert.ai ha acumulado una profunda experiencia en el dominio de los seguros, la tecnología, los servicios financieros, los medios de comunicación y gobierno. La plataforma expert.ai incluye modelos de conocimiento que aprovechan esa experiencia con fórmulas basadas en reglas que contienen conceptos y relaciones específicos del sector, la función o el caso de uso. Son modelos listos para usar que ayudan a mejorar rápidamente la precisión de los resultados de procesamiento lingüístico y sacar a la luz nuevos conocimientos a partir de datos no estructurados.
La posibilidad de “integrar la inteligencia desde el principio” en los proyectos permite proporcionar a cada miembro del equipo flujos de trabajo intuitivos y fáciles de usar, así como herramientas que aceleran el desarrollo de soluciones de comprensión del lenguaje personalizadas y explicables.
Desarrollo más rápido de proyectos de procesamiento del lenguaje
Los modelos de conocimiento aprovechan de manera instantánea la información propia del negocio para crear soluciones de NLP (procesamiento del lenguaje natural) personalizadas con la plataforma expert.ai. Es posible clasificar los documentos y extraer datos relevantes para casos de uso específicos de negocio con un alto nivel de precisión y explicabilidad gracias al enfoque híbrido de expert.ai.
A continuación, figura una lista de modelos de conocimiento disponibles en expert.ai. Todos los días se añaden modelos nuevos. Si no ves el que necesitas para tu proyecto, habla con nosotros.
