Rendi expert.ai Platform “smart from the start” grazie alla conoscenza specifica di settore
Comprendere il linguaggio è difficile. Comprendere il gergo di un determinato settore o la terminologia specifica relativa ai prodotti di un’azienda lo è ancora di più. Almeno finora.
Con la realizzazione di numerosi progetti basati sulla comprensione del linguaggio naturale, expert.ai ha maturato un’ampia esperienza in diversi settori, tra cui tra cui quello assicurativo, tecnologico, dei servizi finanziari e dei media. Expert.ai Platform include modelli di conoscenza (knowledge models) che applicano l’esperienza e la conoscenza di settore a modelli basati su regole, che contengono concetti e relazioni tra concetti inerenti determinati use case e settori. Grazie a questa conoscenza pronte all’uso, aziende e organizzazioni possono migliorare rapidamente il livello di accuratezza delle soluzioni basate sul linguaggio naturale e far emergere nuove informazioni rilevanti dai dati non strutturati a disposizione.
Rendi efficiente lo sviluppo della tua soluzione basata sul linguaggio naturale fin da subito (“smart from the start”), mettendo a disposizione workflow e strumenti intuitivi e facili da usare per tutti i membri del team.
Le soluzioni sviluppate sfruttando i modelli di conoscenza e la piattaforma di expert.ai sono caratterizzate da un approccio:
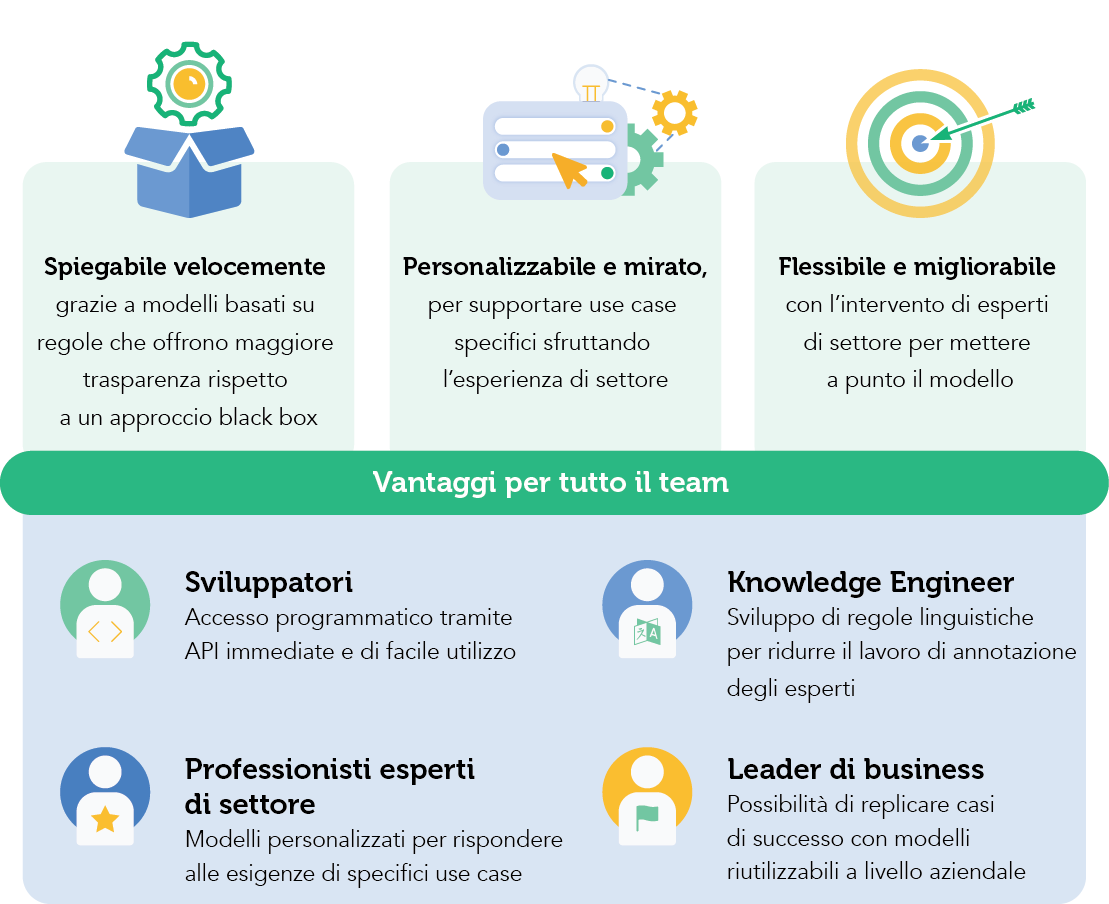
Maggior rapidità nello sviluppo di progetti in linguaggio naturale
I knowledge model sfruttano una conoscenza di settore approfondita e pronta all’uso che offre un vantaggio iniziale nello sviluppo di soluzioni personalizzate di natural language. L’approccio di expert.ai consente infatti di categorizzare documenti ed estrarre dati rilevanti per specifici use case con grande accuratezza e trasparenza.
Di seguito sono descritti alcuni dei modelli di conoscenza già disponibili, ma nuovi knowledge model vengono aggiunti costantemente.
Contattaci se non trovi subito un modello che soddisfa le esigenze del tuo progetto in linguaggio naturale!

