
If there is a single task that best represents natural language processing (NLP) problems, it is document classification.
Generations of NLP techniques were first tested on this problem, including simple algorithms (e.g., Bayes classifiers and K-Nearest Neighbor), machine learning, neural networks and recent advanced deep learning models. Today, it remains a test field for most AI proposals.
In a nutshell, the document classification (or categorization) problem consists of assigning one or more category “labels” to documents, depending on the content (or other information). These labels belong to a predefined set of categories, shown as a list or a tree-shaped structure (known as a taxonomy), or in general a classification scheme.
The labels can be broken down into any number of categories, including:
- Topic
- Document type
- Genre
- Industry
- Geographical information
- Emotions
Assigning labels to documents serves many purposes. Common uses include:
- Routing incoming documents, from simple spam filters to complex document workflows;
- Storing rich information within documents, making it available to search and analytics engines;
- Exploiting identified information and reusing or reselling it as knowledge;
- Identifying the language, source or genre of a document;
- Assessing readability and sentiment;
- Triaging articles to identify relevant ones.
The Art of Knowledge Modeling

A fundamental but little-known aspect of taxonomies is that they are almost always arbitrary. What may appear to be a standardized list of categories is likely to differ from one organization to the next based on their priorities and point of view. Thus, classification schemes are driven by business purpose.
The challenge with categories is that they are often inconsistent, overlap with one another or fail to cover an entire input range. This leads to documents belonging to any number of categories. As such, schemes do not need to be homogeneous. Rather, you can select certain categories for topics and others for document type as they align to your business purposes.
There are plenty of ways to solve this problem. For simple cases with a few well-defined and distinct categories, you just need annotated documents available to use as a training set. That means several examples of which you already know the expected result (i.e., pre-labeled documents that are manually created or from historic data). Sometimes it is easy to get them; less so in other instances, often due to cost.
When you have numerous categories (or when they significantly overlap), more volume and higher quality data is critical to the training set. Also, when the category tree is very deep (i.e., there are many dependencies or tiny nuances among categories), your examples must be even more precise.
This can become a major problem, as you get to a point where you cannot accumulate enough detail in the training set to cover all the wordings and cases — either because they don’t exist or are too expensive to obtain.
Learning from Knowledge Instead of Data
Expert.ai technology uses proprietary components that implement a supervised learning strategy with custom machine learning algorithms. All of the model training is performed by strong NLU analysis which essentially resolves the feature engineering problem. This means we are not just feeding the model text, but rather the understanding from the expert.ai core.
From there, the learning algorithm leverages its knowledge to generalize the model. In doing so, it makes the model more powerful, enabling it to effectively understand the value within unseen documents, unlike a standard learning algorithm.
For example, we could understand a category to be related to the state of New York when many New York cities and towns are mentioned in the training set. Then, we could successfully identify documents about the Hudson River, despite no mention of it in the annotated data.
At a first glance, this works like most other models. You start with an annotated document set, train the system, test it, then use it. The key difference here is that this model is not built in a black box where the model cannot read and must be trained on a continual basis. This model writes its own general cognitive rules, just as a human would with our development tools.
This creates a fully explainable AI workflow, as outputs are representative of human analysis and quality control. As a result, we can quickly and automatically train, test and potentially bring systems to production with a rapid development model — all while thoroughly testing and manually refining the rules for optimal quality.
The Best of Both Worlds
We can retrain as any other statistical model can, but the manual tuning option offers unprecedented quality control — much like a symbolic method. This enables us to address errors and make quality improvements without relying on the availability of training sets.
On the other hand, statistical models leverage a CPU for training and endure a long, complex and unsafe fine-tuning process. Symbolic methods take time up front to collect knowledge and establish code rules, but they offer more powerful and effective tuning.
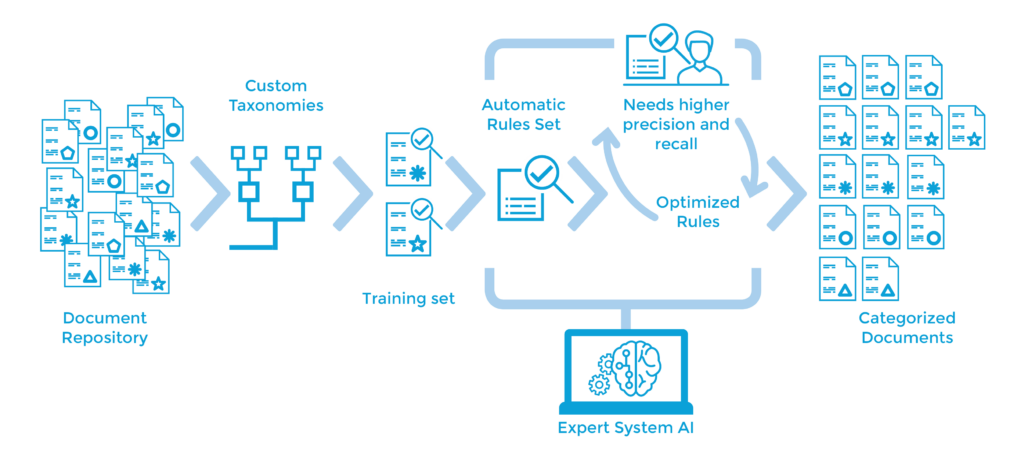
The whole system is fully integrated into the cognitive project lifecycle within the expert.ai platform, where you can perform joint testing and development, regression checks, refinements and extensions.
The expert.ai platform is an easy win for most complex AI problems. We can jumpstart a classifier such as a statistical model, while maintaining the superior quality of symbolic models. This has enabled expert.ai to successfully implement countless enterprise NLU-based document classifier models for organizations around the world. Are you ready to build your own?


