

How We Built a Better Solution to the Misinformation Epidemic

This work was conducted in the context of project Co-inform, funded by the EU under grant 770302. Further information, including details on the architecture, implementation, and experimental results can be found in our paper Linked Credibility Reviews for Explainable Misinformation Detection, which was awarded Best Research Paper at the International Semantic Web Conference, held in November 2020. Both our ISWC 2020 talk and a GitHub repository including our experimental settings are also available.
Misinformation is not a new issue, but it has been sounding alarm bells due to its steep growth in recent years. Due to the pace of news cycles combined with social media, the information bubbles misinformation creates has increasingly evolved into an ecosystem that thrives with influence from various societal effects.
Tackling misinformation (or “fake news” as it is often referred to) is not something that can be achieved by a single organization — as evidenced by the struggles of major social networks — as it requires decentralization, common conceptualizations, transparency and collaboration.
Technical solutions for computer-aided misinformation detection and fact-checking have recently been proposed and are essential due to the scale of the Web. However, a lack of hand-curated data, maturity and scope of current AI systems means that assessing veracity is not always feasible. Hence, the value of the current systems should not be placed so much on their accuracy, but rather their capacity to retrieve potentially relevant information that can help human fact-checkers — the main intended users of such systems who are ultimately responsible for verifying/filtering the results such systems provide.
The ongoing challenge is to develop an automated system that can help the general public assess the credibility of web content. The key caveat here is that the AI system must provide explainable results. This highlights the need for hybrid approaches that combine the best of deep learning-based approaches and symbolic knowledge graphs to build a human-like understanding of language at scale. This establishes a necessary level of trust between large platforms, fact-checkers and the general public — as well as other stakeholders like policymakers, journalists, webmasters and influencers.
The Existing Efforts to Tackle Misinformation
The idea of automating (part of) the fact-checking process is relatively recent. ClaimBuster proposed the first automated fact-checking system and its architecture is mostly still valid, with a database of fact-checks and components for monitoring web sources, spotting claims and matching them to previously fact-checked claims. Other similar services and projects include Truly Media, InVID and CrowdTangle. These systems are mainly intended to be used by professional fact-checkers or journalists, who can evaluate whether the retrieved fact-check article is relevant for the identified claim.
These automated systems rarely aim to predict the accuracy of the content, but rather (rightly) leave that job to the journalist or fact-checker who uses the system. Many of these systems provide valuable REST APIs to access their services, but as they use custom schemas, they are difficult to compose and inspect as they are not machine-interpretable or explainable.
Besides full-fledged systems for aiding in fact-checking, there are also various strands of research focusing on specific computational tasks needed to identify misinformation or assess the accuracy or veracity of web content based on ground credibility signals. Some low-level NLP tasks include check-worthiness and stance detection, while others aim to use text classification as a means of detecting deceptive language.
However, there remains some missing elements to these systems, which we sought to address in our own model. Such elements have to do with decentralization (not one single organization should own the exclusive stewardship of this information) and explainability (how to represent credibility in a way that is machine-readable, interoperable, and understandable by human experts).
How We Detect Misinformation
Our solution proposes an architecture based on the core concept of credibility reviews (CRs) that can be used to build networks of distributed bots that collaborate to detect misinformation. Credibility reviews serve as building blocks to compose graphs of:
- web content,
- existing credibility signals like fact-checked claims and reputation reviews of websites, and
- automatically computed reviews.
We implement such architecture on top of a lightweight extension to Schema.org and services that execute generic NLP tasks for semantic similarity and stance detection. Schema.org was an excellent starting point since it already provided suitable schema types for data items on the web for which credibility reviews would be beneficial (like review and rating), as well as properties for expressing basic provenance information and meronymy (hasPart). The overall Schema.org-based data model including our extensions (in bold) is depicted in the following figure*:
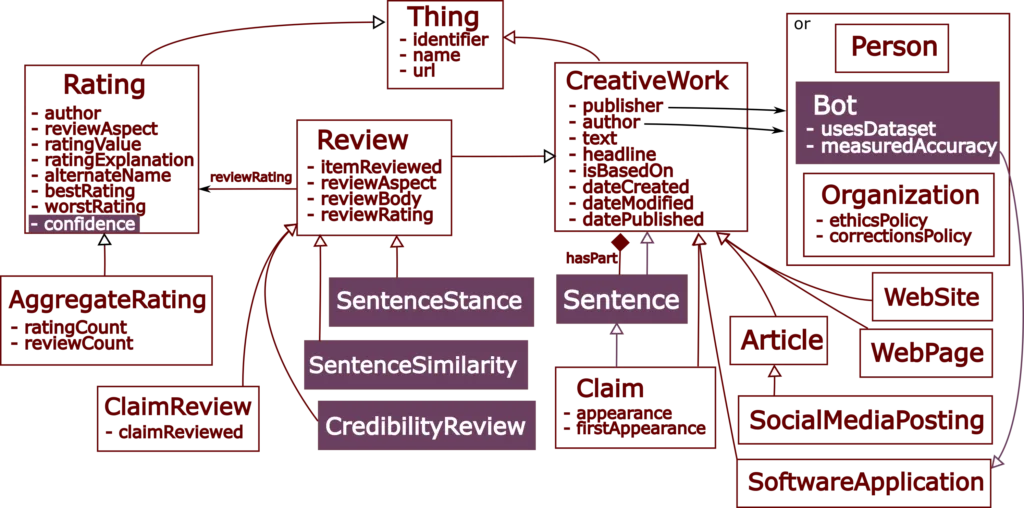
*We focused on credibility reviews for textual web content and left other modalities as future work.
Our CR bots implement several strategies to review the credibility of a claim and then annotate them using the data model previously described. This includes:
- Ground credibility signal lookup from some trusted source. CR bots that implement this strategy will (i) generate a query based on the data item to review and (ii) convert the retrieved ground credibility signal into a CR.
- Linking the “item to review” with other data items of the same type, for which a CR is already available at some fact-checking database.
- Decomposing, whereby the bot identifies relevant parts of the “item to review” and requests CRs for those parts. Similar to linking bots, these require derivation of new credibility ratings and confidences based on the relationship between the whole and the parts, then aggregating these into the CR for the whole item.
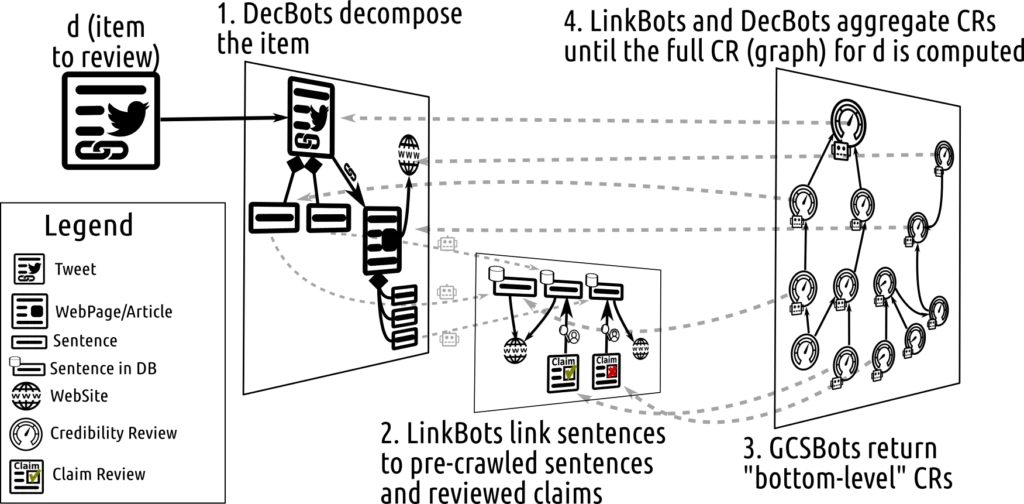
The diagram below depicts how the various CR bots compose and collaborate to review a tweet.
The Results and What’s Next
Our experiments demonstrate the capabilities and added value of our approach. We have evaluated our work on existing datasets of social media posts, fake news and political speeches, demonstrating several advantages over existing systems, including:
- extensibility,
- domain-independence,
- composability,
- explainability, and
- transparency via provenance.
We obtain competitive results without required fine-tuning and establish a new state-of-the-art (Clef’18 CheckThat! Factuality) task. We also identified promising areas for improvement and further research. We plan to:
- Further improve stance detection models by fine-tuning and testing on additional datasets;
- Perform an ablation test on an improved version of our implementation to understand the impact of including or omitting certain bots and datasets.
- Evaluate both the understandability, usefulness and accuracy of the generated explanations following a crowdsourcing approach to involve a considerably large number of evaluators.
Aside from our own plans, a single organization or team cannot tackle and resolve every issue necessary to achieve high-accuracy credibility analysis of web content. This is exactly why we propose the Linked Credibility Review architecture, which enables the distributed collaboration of fact-checkers, deep-learning service developers, database curators, journalists and citizens to build an ecosystem where more advanced, multi-perspective and accurate credibility analyses are possible.







